Fine-Tuning Silently Breaks AI Safety Monitors
TL;DR. I tracked a linear shortcut-detection probe (where “shortcuts” are code solutions that pass the visible test cases but fail hidden edge-case tests) across five rounds of SFT on Qwen2.5-Coder-7B. The probe direction rotates 40–70° within the first training step, but additive steering along the old direction still produces clean dose-response curves — so standard evaluation says the monitor “still works.” The Arditi et al. ablation test says otherwise: the direction is sufficient but not necessary.
Epistemic status. One model, one feature, one training recipe. I’m confident the phenomenon exists and is present from the first SFT round; the adversarial version (gradient pressure against a frozen probe) is the important next experiment. Full paper here.
The threat scenario, made concrete
Imagine a safety team deploys a probe-based monitor that detects a behavior — reward hacking, deception, whatever. The model gets fine-tuned on new data. They re-check:
- Probe AUROC: 0.89, down from 0.98. Noticeable but not alarming.
- Steering test: adding −α·d̂ to the residual stream still reduces the behavior with a clean dose-response curve. Direction “still works.”
- They ship.
What they don’t know is that the direction their monitor watches is no longer the axis the model uses. The monitor is reading a ghost. This isn’t speculative — Anthropic’s Claude Mythos Preview system card flagged it qualitatively during alignment training:
“The causal effects of individual features often changed over the course of post-training, making it difficult to attribute behavioral changes merely to increases or decreases in particular feature activations.” — Mythos Preview System Card, §4.5.3.4
Mythos reports the phenomenon as an operational difficulty inside a production run. This post is the controlled measurement: same probe, same trajectory, three interventions, quantified.
The core result: one figure
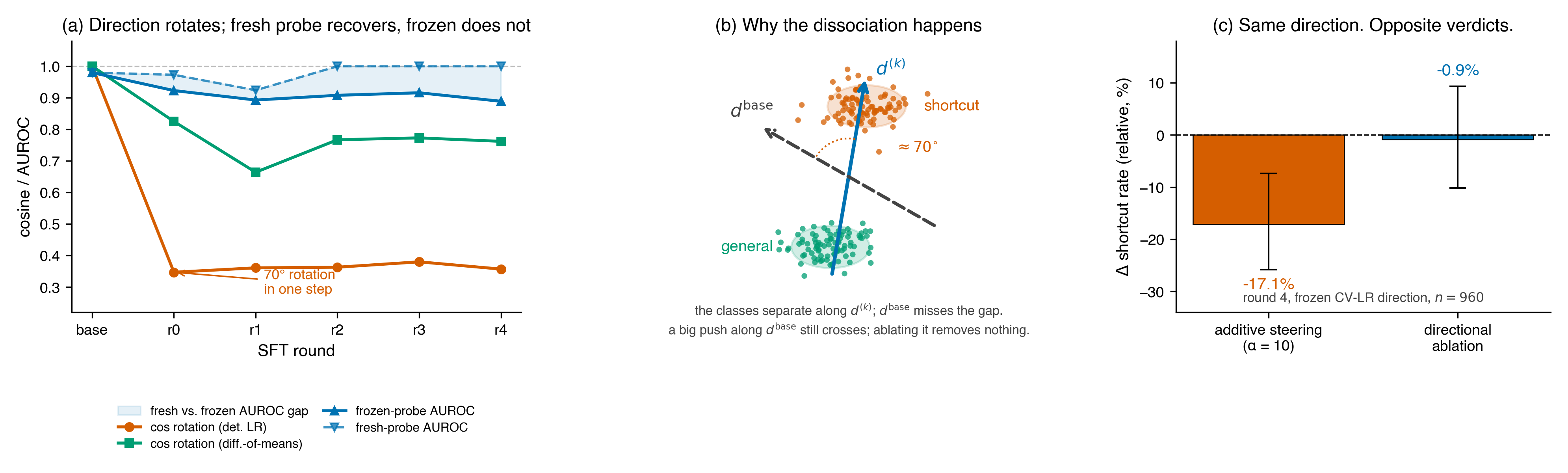
Sufficiency says yes; necessity says no. Additive steering reports a large, significant effect (−17.1% at α=10, CI excludes zero). The Arditi ablation test — projecting d̂ out at every layer-11 token — reports essentially nothing (−0.9%, CI crosses zero). Same direction. Same checkpoint. Opposite verdicts.
This is the sufficiency–necessity gap: a frozen direction along which you can still push the model’s behavior, even though that direction is no longer the axis the model uses to represent the behavior. A high-norm push along a correlated direction crosses the decision boundary.
The decision boundary is not at the direction the push points along.
What’s happening mechanically
The readable direction rotates within one SFT step. Across three extraction methods (LogisticRegressionCV, deterministic LR at C=1, and difference-of-means), the cosine between the base direction and every post-base direction is substantially below 1.0 by round 0 — the first SFT round:
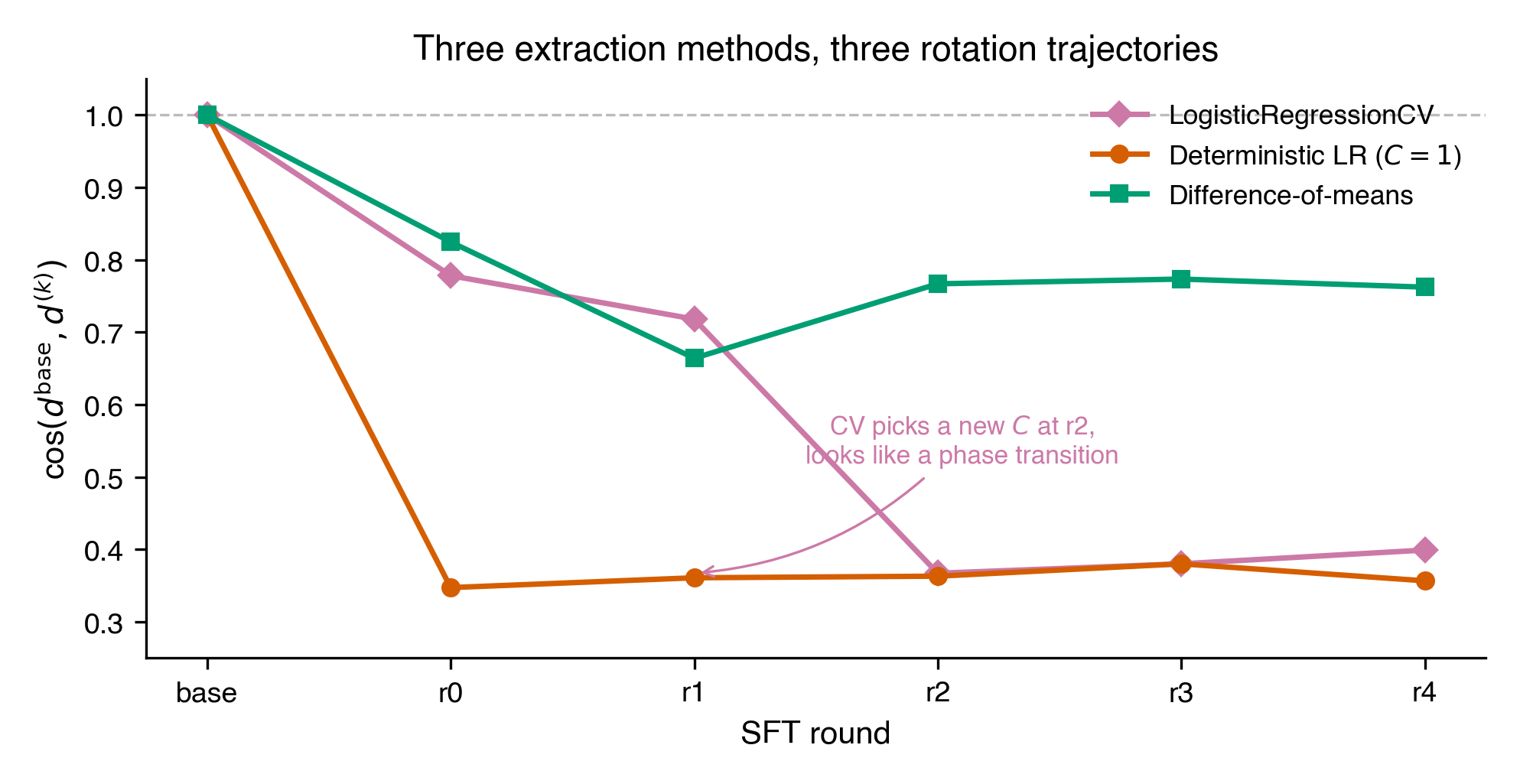
Meanwhile, a fresh probe refit at each checkpoint recovers AUROC ≥ 0.92. The feature hasn’t decayed — it’s become more separable, not less. The coordinates moved.
In 3584 dimensions, the best classifier and the actual concept direction are nearly orthogonal. On step-0 activations, cos(LR, DoM) ≈ 0.26. The LR direction has enough norm at α=10 to cross the decision boundary by brute force, even though it doesn’t point along the axis the model actually uses — which is why projecting it out removes almost nothing.
A methodological aside. The initial round-4, α=5 measurement returned +0.7% (CI [−9.2, +11.8]), which almost anchored a “dose dead zone” narrative. Roughly $10 of A100 compute later, the re-measurement returned −9.8% (CI [−18.4, −0.2]). The entire framing of the paper turned on one re-run. At n=960 with single-digit effects, single-point measurements at the edge of their CI can support qualitatively different stories than the truth.
Only one extraction method survives the necessity test
Running the ablation battery across all three extraction methods and both frozen (fit at base) and fresh (refit at round 4) directions:
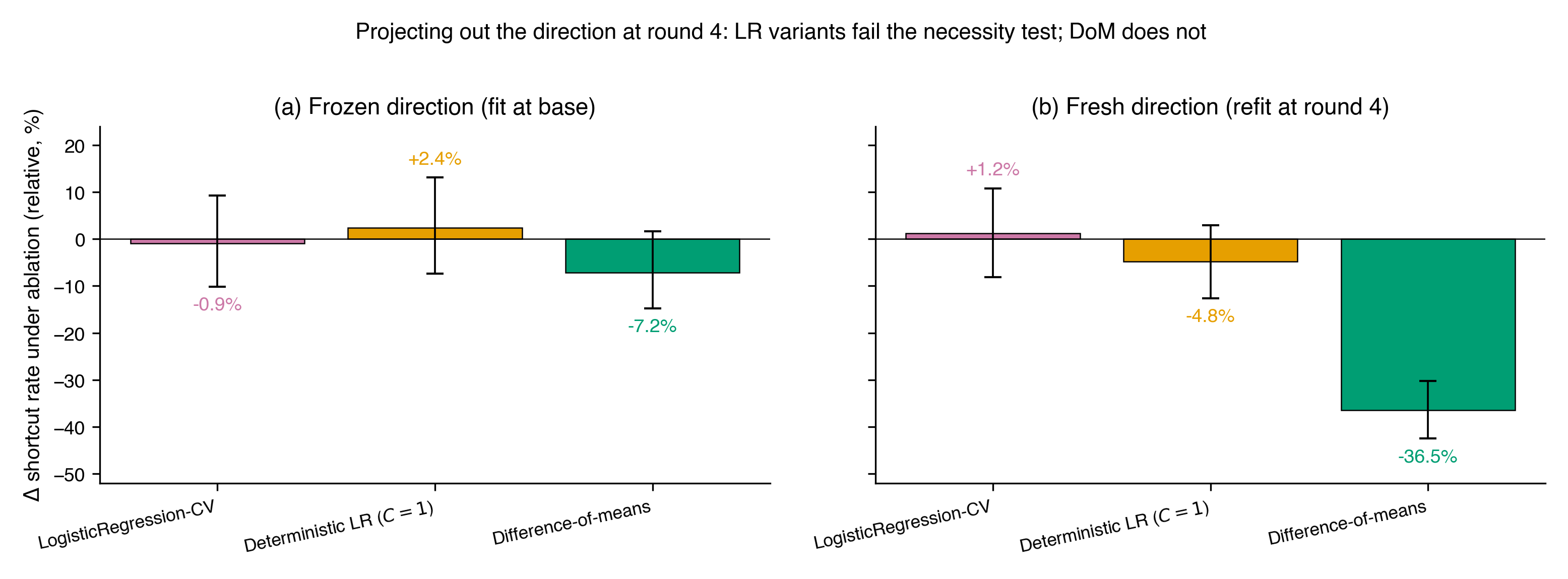
Difference-of-means is the only extraction method that retains causal necessity through training. Frozen DoM: −7.2% (p=0.92). Both LR variants fail the necessity test at both checkpoints, including the fresh CV-LR direction at in-sample AUROC 1.000. A probe with AUROC 1.0 can be completely causally disconnected from the feature it classifies.
The fresh difference-of-means direction at round 4 produces a −36.5% shortcut reduction under ablation — larger than any additive steering effect at any checkpoint. The feature hasn’t decayed; it has reorganized into a sharper, more causally concentrated subspace. But you only see this if you’re using the right extraction method and refitting at the current checkpoint. Freeze the LR direction at base, and you get −0.9%.
The extraction method that Arditi et al. and RepE already default to on stability grounds is the one — maybe the only one — that retains causal faithfulness under training pressure.
Update: the dissociation is present from round 0. I re-ran the frozen-direction ablation at rounds 0 and 2 to locate where in training the necessity loss kicks in. The answer is: immediately.
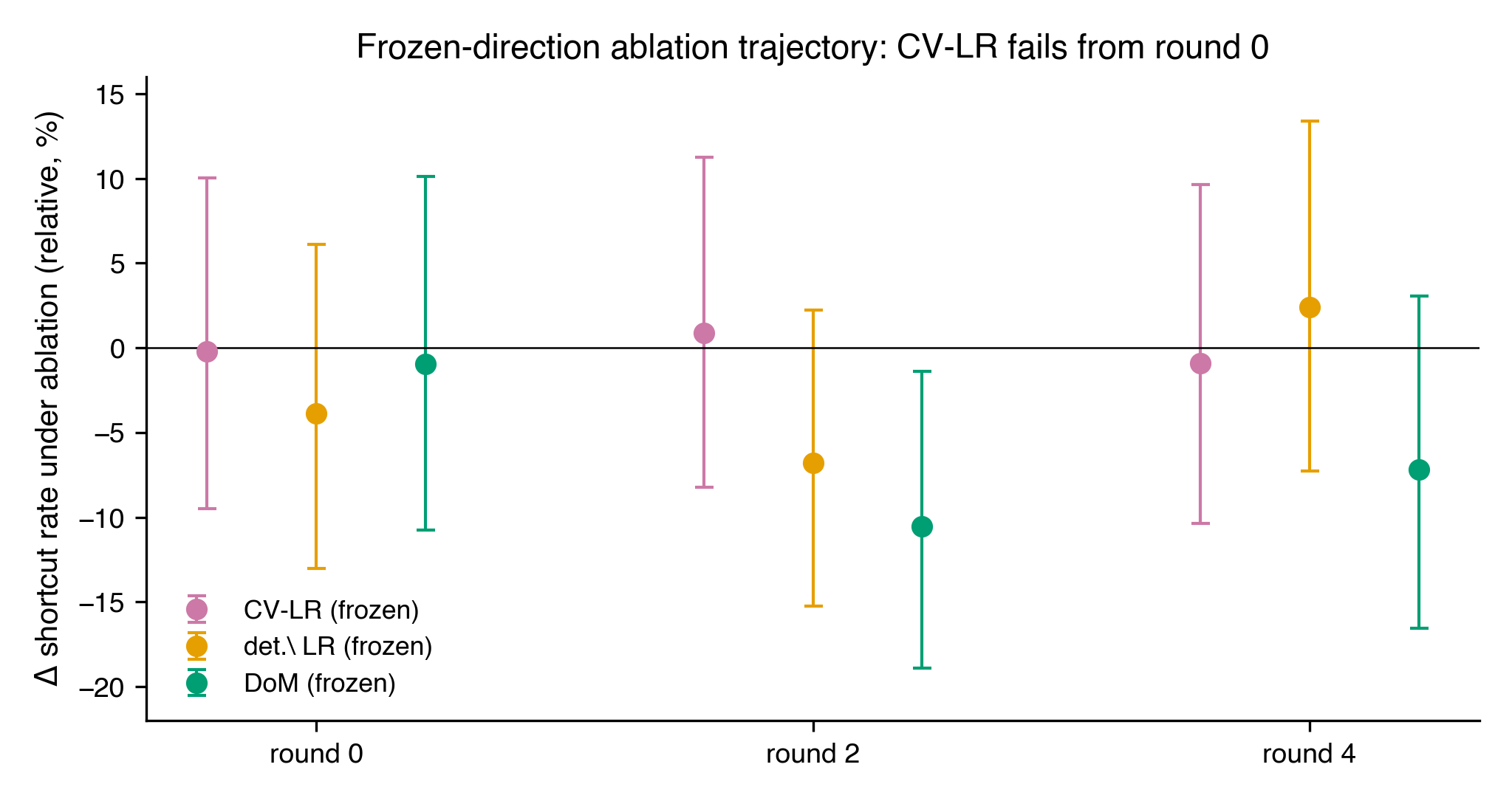
CV-LR frozen gives Δ = −0.2% [−9.5, +10.1] at round 0, +0.9% [−8.3, +11.3] at round 2, and −0.9% [−10.4, +9.6] at round 4 — null at every checkpoint. Deterministic LR is similarly null throughout. DoM is the only method with a CI-excluding-zero effect anywhere, and even DoM is null at round 0 (Δ = −1.0% [−10.8, +10.1]); its peak is at round 2 (−10.5% [−18.9, −1.4]). The frozen CV-LR direction is magnitude-only from the very first SFT step — not a late-checkpoint transition, but the starting condition after any amount of fine-tuning.
What a safety team should do differently tomorrow
Three concrete changes for anyone deploying a linear probe as a runtime monitor:
- Refit the probe whenever retraining occurs. Freezing directions across training steps is the core bug. If you must freeze, use difference-of-means — it’s the only method I tested that survives the rotation with measurable causal necessity.
- Run the projective-ablation test alongside any steering-based validation. Additive steering alone is a sufficiency result. Monotonic dose-response is consistent with the direction being the causal axis or being a correlated proxy whose large-α push happens to cross a decision boundary. Ablation is what separates them.
- Treat AUROC as a calibration check, not a causal-faithfulness check. We found a probe with AUROC 1.0 that was completely causally disconnected from the feature it classified. AUROC measures the existence of a separating hyperplane, not whether the model is on the right side of it for the right reason.
Open questions
- Under adversarial pressure — a training loss that directly rewards lowering the probe’s score — does difference-of-means retain necessity, or does it fail too?
- Does the rotation happen in all fine-tuning regimes, or is iterative SFT pathological?
- Is there a subspace-tracking analog to probe retraining — something that follows the feature rather than rediscovering it?
Limitations
One model, one probe-derived feature (shortcut vs. general code), one training recipe (iterative rejection-sampling SFT on CodeContests). Shortcut/general is capability-entangled in a way that refusal or emotion directions may not be. The adversarial version — adding a loss term that rewards lowering the probe’s score on shortcut completions — is the experiment that would convert this existence proof into a quantitative monitor-robustness benchmark. My prediction: under direct gradient pressure, the AUROC decay happens faster and the sufficiency–necessity dissociation appears earlier and larger.
If you’re running deployment monitors on production models, I’d like to know whether your protocol would have caught this. Comments welcome.